Cap. 5 Distribución de Frecuencias
Usada principalmente para reunir y resumir una gran cantidad de datos. De tal manera que sea interpretable fácilmente para el lector.
Para obtener los cálculos de una distribución de frecuencias haremos uso de algunos paquetes.
Ingresamos el conjunto de datos
x<-c(61,33,35,74,48,53,53,48,23,19,15,57,72,40,27,25,75,66,34,27,38,16,42,57,27,59,37,63,71,48)#Debera instalar el paquete que vamos a llamar
library(fdth) # carga la extensión fdth (para el calculo de distribución de frecuencias.##
## Attaching package: 'fdth'## The following objects are masked from 'package:stats':
##
## sd, vardist <- fdt(x,breaks="Sturges") # calcula la distribución de frecuencias utilizando la regla Sturge
dist #nos brinda una tabla con los calculos de la distribución de frecuencias.## Class limits f rf rf(%) cf cf(%)
## [15,25) 4 0.13 13.3 4 13.3
## [25,35) 7 0.23 23.3 11 36.7
## [35,45) 4 0.13 13.3 15 50.0
## [45,55) 5 0.17 16.7 20 66.7
## [55,66) 5 0.17 16.7 25 83.3
## [66,76) 5 0.17 16.7 30 100.0#Donde
#f= frecuencia absoluta
#rf= frecuencia relativa
#rf(%) frecuencia relativa porcentual
#cf= frecuencia acumulada
#cf(%)=frecuencia acumulada porcentualpar(mfrow=c(3,2)) # particiona mi ventana grafica en 3x2.hist(x, breaks = "Sturges") #histograma utilizando el número de clases según Sturge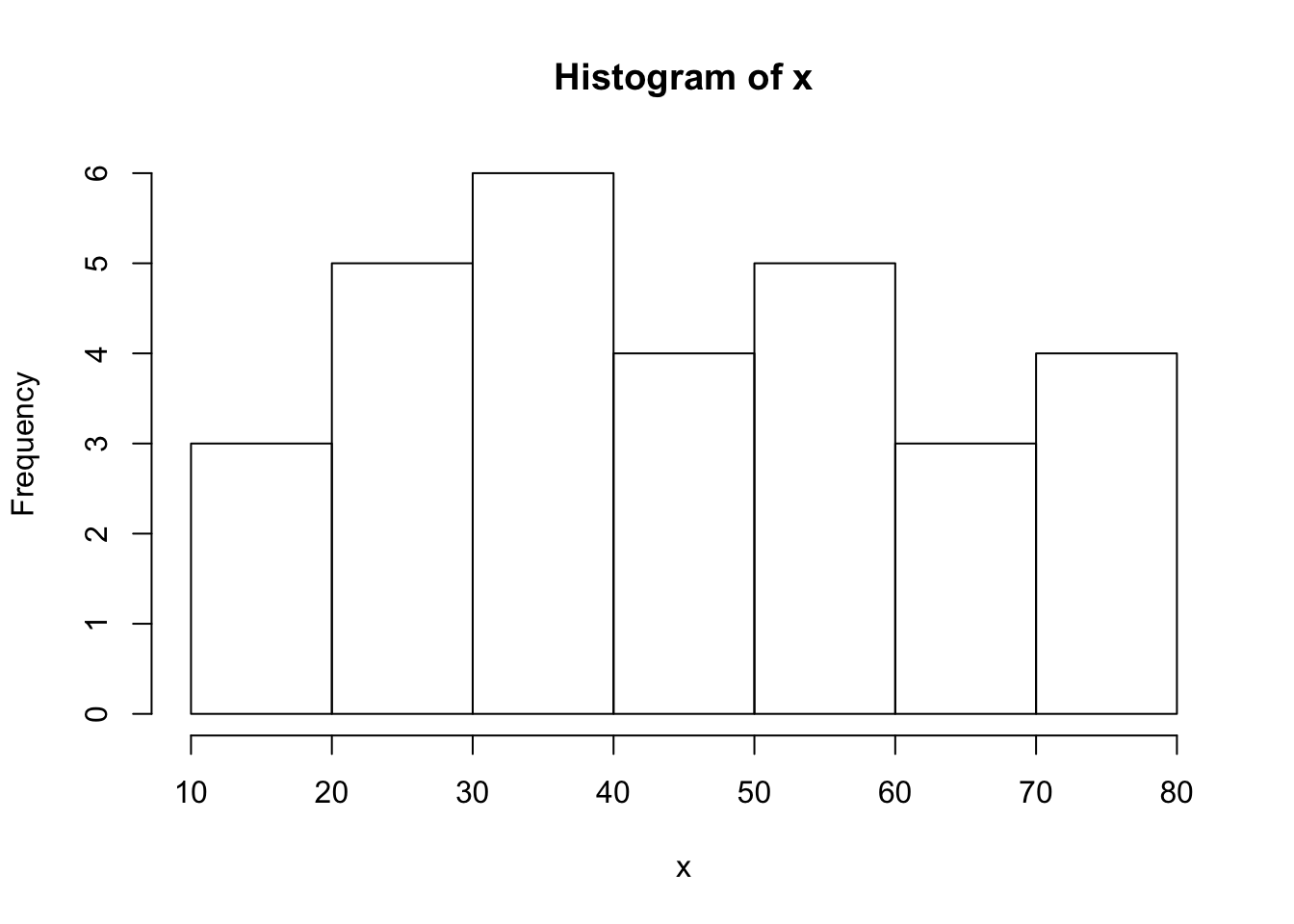
plot(dist, type="cfh") #histograma de frecuencias acumulada
plot(dist, type="cfp") #polìgono de frecuencias acumulado
#explore los otros argumentos graficos,"fh", "fp", "rfh", "rfp", "rfph", "rfpp", "d", "cdh", "cdp", "cfh", "cfp", "cfph", "cfpp"plot(dist, type="fh")
plot(dist, type="fh", col="#4E46EB") #si desea añadir color a su grafico
5.1 Utilizando bases de datos
#Utilice el set de datos que presenta R. Para visualizarlos utilice la siguiente función
data() # visualiza los datos de R y asociados a las extensiones que ha cargado
Loblolly #nombre del set de datos que utilizaremos
head(Loblolly) #visualiza los titulos que contiene los datos Loblolly, asi como una parte del contenido de los datosPara crear la distribución de frecuencia, buscamos primeramente el rango de los valores de la variable de interés, en nuestro caso trabajaremos con la variable “age”.
datosfreq<- Loblolly $ age #utilizamos el simbolo de $ para separar de los datos la variable de interes.
datosfreq## [1] 3 5 10 15 20 25 3 5 10 15 20 25 3 5 10 15 20
## [18] 25 3 5 10 15 20 25 3 5 10 15 20 25 3 5 10 15
## [35] 20 25 3 5 10 15 20 25 3 5 10 15 20 25 3 5 10
## [52] 15 20 25 3 5 10 15 20 25 3 5 10 15 20 25 3 5
## [69] 10 15 20 25 3 5 10 15 20 25 3 5 10 15 20 25range(datosfreq) #observamos el rango de duración, en nuestro caso, va de 3 a 25## [1] 3 25dist1 <- fdt(Loblolly $ age,breaks="Sturges")
dist1## Class limits f rf rf(%) cf cf(%)
## [3,5.8) 28 0.33 33.3 28 33.3
## [5.8,8.5) 0 0.00 0.0 28 33.3
## [8.5,11) 14 0.17 16.7 42 50.0
## [11,14) 0 0.00 0.0 42 50.0
## [14,17) 14 0.17 16.7 56 66.7
## [17,20) 0 0.00 0.0 56 66.7
## [20,22) 14 0.17 16.7 70 83.3
## [22,25) 14 0.17 16.7 84 100.0#Si queremos utilizar un rango diferente (start, end) con amplitud definida (h), utilizamos lo siguiente.
dist2 <- fdt(Loblolly $ age, start=3, end=28, h=5)
dist2## Class limits f rf rf(%) cf cf(%)
## [3,8) 28 0.33 33.3 28 33.3
## [8,13) 14 0.17 16.7 42 50.0
## [13,18) 14 0.17 16.7 56 66.7
## [18,23) 14 0.17 16.7 70 83.3
## [23,28) 14 0.17 16.7 84 100.0#Si quisieramos utilizar un número de clases diferente utilizamos el argumento k.
dist3 <- fdt(Loblolly $ age, k=9) #utilizamos k para determinar el número de clases deseado.
dist3## Class limits f rf rf(%) cf cf(%)
## [3,5.4) 28 0.33 33.3 28 33.3
## [5.4,7.9) 0 0.00 0.0 28 33.3
## [7.9,10) 14 0.17 16.7 42 50.0
## [10,13) 0 0.00 0.0 42 50.0
## [13,15) 14 0.17 16.7 56 66.7
## [15,18) 0 0.00 0.0 56 66.7
## [18,20) 14 0.17 16.7 70 83.3
## [20,23) 0 0.00 0.0 70 83.3
## [23,25) 14 0.17 16.7 84 100.05.2 Obtención del número de clases en la distribución de frecuencias
#Caso 1.
#Regla de Sturges
#Utilizamos la formula
#K = 1+(Log(n) / Log(2))
#en donde K es el número de clases (intervalos), y n el número de muestras.
#Si observamos los datos Loblolly contiene 84 datos
k<-(1+log(84) /log(2)) #obtenemos el número de clases sugeridas para nuestros datos
k## [1] 7.39Caso 2 ## Regla de Sturges
K=1 + (3.322*Log10(n))
Dimensión de los intervalos de clase = R/k Donde R= al rango de los datos k= rango rango=(max-min)
k1<-1 + (3.322*log10(84))
k1## [1] 7.39#Seria el número de clases a formar (7 aproximadamente)
#o
#Hay una función escrita en R que estima el número de clases
nclass.Sturges(datosfreq)## [1] 8#Esta función nos recomienda 8 clases.
palette() #muestra los colores disponibles## [1] "black" "red" "green3" "blue" "cyan"
## [6] "magenta" "yellow" "gray"par(mfrow=c(3,2)) #permite dividir la ventana de graficos (3 filas, 2 columnas)Utilizaremos la variable “height”"
hist(Loblolly $ height,xlab="cantidad",ylab="frecuencia",main="Histograma", col="green3")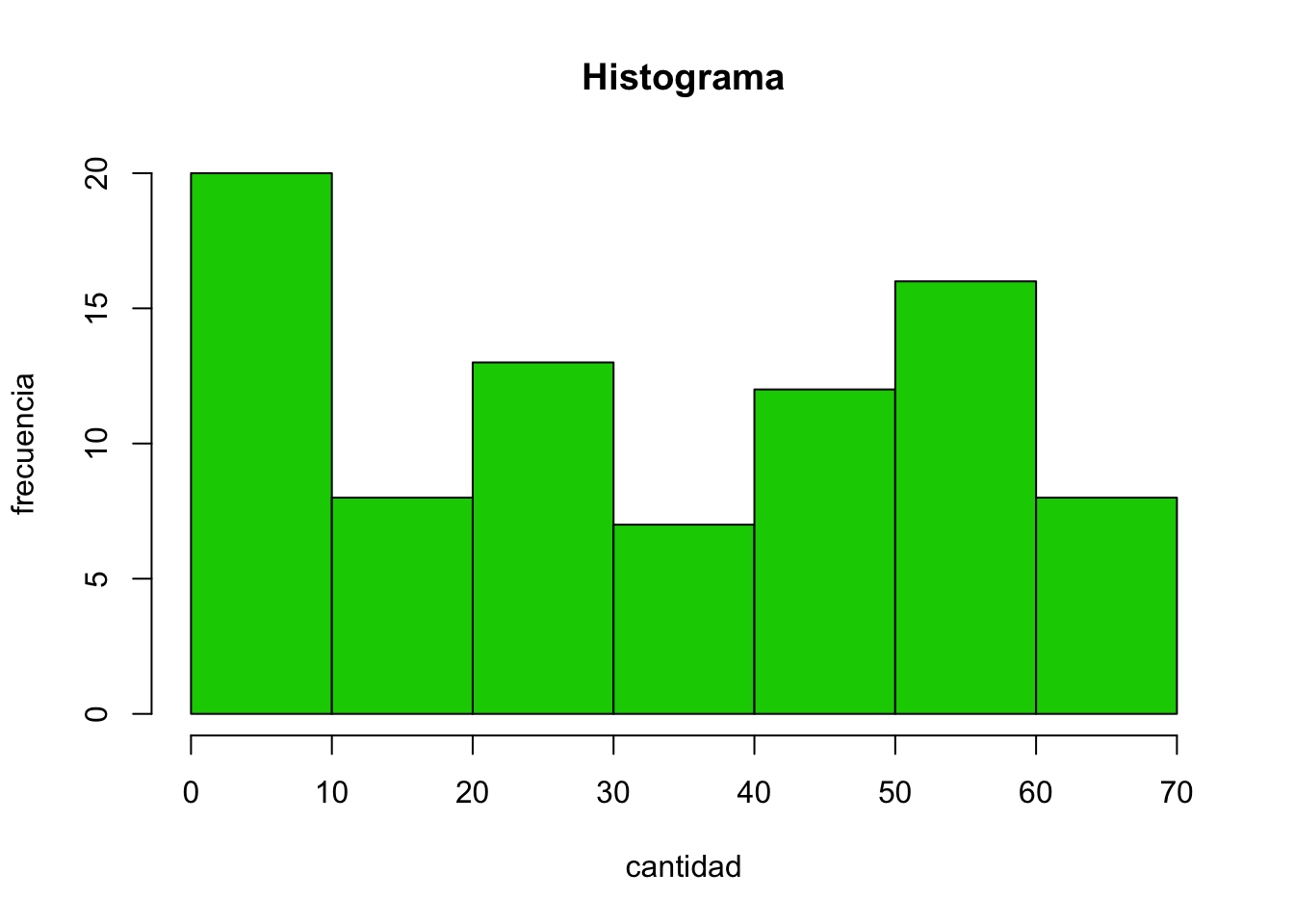
hist(Loblolly $ height, xlab="cantidad",ylab="frecuencia",main="histograma", col="56")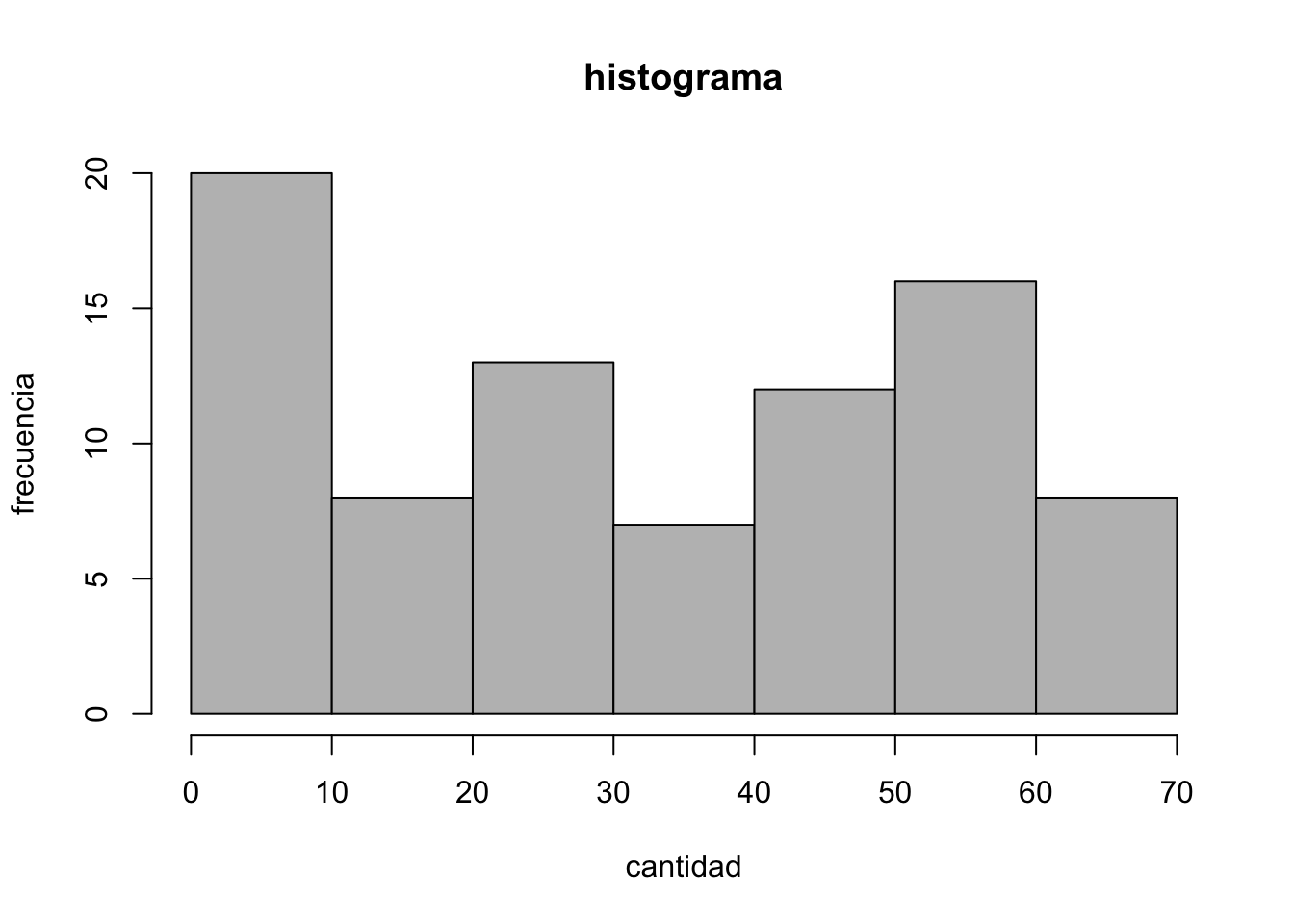
5.3 Práctica
head(Loblolly)## height age Seed
## 1 4.51 3 301
## 15 10.89 5 301
## 29 28.72 10 301
## 43 41.74 15 301
## 57 52.70 20 301
## 71 60.92 25 301attach(Loblolly) #función que adjunta los datos al programa
summary(age) #note que ya no tendremos que separar por $, dado la función attach## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 3.0 5.0 12.5 13.0 20.0 25.0summary(height)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 3.5 10.5 34.0 32.4 51.4 64.15.3.1 Obtenga el set completo de la distribución de frecuencia para la variable “weight”. Interprete la primera clase de la Frec.
5.3.2 Interprete la tercera clase de Frec. rel.
5.3.3 Interprete la segunda clase de Frec. Acum.
5.3.4 Interprete la segunda clase de Frec. Rel. Acum.
5.3.5 Elabore un polígono de frecuencia, agregue un título y color a su figura.
5.3.6 Elabore un polìgono de frecuencia
5.4 Resumen de funciones utilizados en R
#library() Carga un paquete especifico de R
#attach() permite adjuntar los datos de acuerdo a como fueron nombradas las variable
#data() muestra conjunto de datos que contiene los paquetes que ha cargado
#head() visualiza los titulos que contiene los datos
#fdt() función del paquete fdth que permite elaborar distribuciones de frecuencias
#hist() elabora un histograma de frecuencias.
#palette() muestra los colores disponibles
#par(mfrow=c(3,2)) permite dividir la ventana de graficos (3 filas, 2 columnas)
#range() obtiene el rango de datos de un vector
#sort() ordena los datos de la variable de interes en forma ascendente